
SEO vs. LLM-Suche
Wir alle wissen grob, wie funktioniert Google funktioniert: Ein Query, ein Ranking, ca. zehn Links. Der Nutzer klickt meist auf die Anzeigen oder auf den ersten organischen Link.
LLM-basierte Suche ist neu, funktioniert anders und ändert sich monatlich. Stand April 2026 verläuft eine Suche so: Das Modell (ChatGPT, Gemini, Claude) empfängt einen Prompt, zerlegt ihn in Teilfragen & startet für jede eine eigene Suche. Anschließend werden die Ergebnisse gescannt und vielversprechende Seiten gelesen. Relevante Passagen werden extrahiert und zusammengefasst. Der User bekommt daraus eine Antwort mit Zitaten und Quellenangaben.
Wichtig: LLMs verwenden (noch) herkömmliche Suchmaschinen. Das heißt, dass herkömmliches SEO weiterhin der wichtigste Bestandteil ist, um in LLMs zitiert zu werden.
Gehen wir die einzelnen Schritte einmal genauer durch:
Query Fan-Out (QFO)
Google hat den Mechanismus 2025 auf der I/O unter dem Begriff Query Fan-Out formalisiert. Im Kern: Ein einzelner Prompt wird in mehrere semantisch eigenständige Sub-Queries zerlegt, die parallel gegen den Suchindex laufen.
Aus „Was ist die beste AEO Agentur in Hamburg?" werden beispielsweise:
- beste AEO Agentur Hamburg
- AEO Agentur Hamburg Answer Engine Optimization
- Answer Engine Optimization Agentur Deutschland Vergleich
Jeder Sub-Query hat einen leicht anderen Fokus - Mal auf Englisch, mal auf Deutsch, mal mit regionaler Eingrenzung oder Synonymerweiterung. Googles Patent (US20240289407A1) beschreibt acht unterschiedliche Query-Typen, darunter Reformulierungen, komparative Queries und implizite Folgefragen.
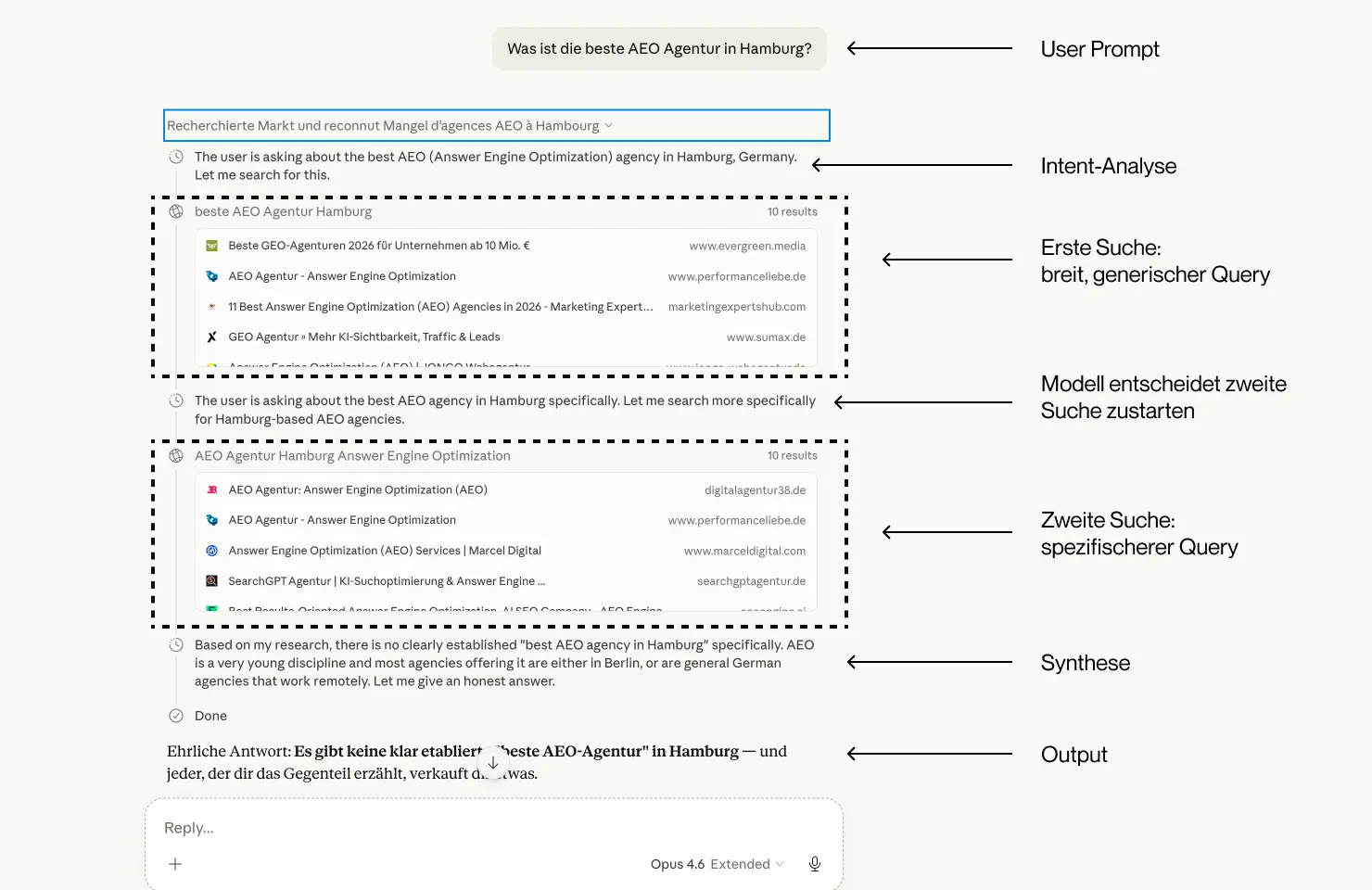
Obwohl Google diesen Begriff und den Mechanismus geprägt hat, nutzen ihn alle Modelle. ChatGPT, Perplexity, Gemini und Google AI Mode verwenden verschiedene Varianten von Fan-Out. Der wichtigste Unterschied liegt im verwendeten Suchindex: ChatGPT sucht über Bing. Perplexity hat einen eigenen Index mit über 200 Milliarden URLs. Google AI Mode nutzt die eigene Infrastruktur. Wer ausschließlich für Google optimiert läuft Gefahr, in dem (vermeintlich) meistgenutzten Modell, ChatGPT, nicht ausreichend präsent zu sein.
Laut Nectiv lösen 31 % aller ChatGPT-Prompts mindestens eine Websuche aus, mit durchschnittlich 2,17 Suchanfragen pro Prompt (Stand Oktober 2025). Mehr als zwei Drittel werden also aus dem parametrischen Wissen des Modells beantwortet. Hier präsent zu sein ist deutlich komplizierter und kaum trackbar. Dieses Verhältnis ändert sich aber stetig und man kann davon ausgehen, dass bald fast alle Prompts mit einem QFO unterstützt werden.
Fan-Out-Queries können selber eingesehen werden
Die Sub-Queries, die ChatGPT generiert, sind für User mit einem Trick selber einsehbar und im Netzwerk-Traffic des Browsers dokumentiert. Über die Developer Tools (Network-Tab, Conversation-ID als Filter, Response-Tab, Suche nach search_model_queries) lassen sich die exakten Bing-Queries extrahieren, die das Modell aus einem Prompt ableitet.
Das Feld search_model_queries im Response-Payload enthält typischerweise 3 bis 15 eigenständige Suchanfragen pro Prompt. Chrome Extensions automatisieren die Extraktion. Perplexity zeigt seine Sub-Queries direkt in der Oberfläche an - die transparenteste Plattform in dieser Hinsicht.
Strategisch relevant ist nicht nur der einzelne Query - Fan-Out-Queries sind synthetisch und variieren zwischen Sessions. Relevant sind die thematischen Cluster, die sich über mehrere Tests stabilisieren. Sie zeigen, welche semantischen Räume das Modell mit Ihrer Kategorie assoziiert und wo Ihre Inhalte fehlen.
RAG-Pipeline extrahiert Erkenntnisse
Da QFOs extrem viel Context geben (viel wertvolles aber auch viel Overhead), wird eine RAG-Pipeline (Retrieval-Augmented Generation) verwendet, die bestimmt was in der Antwrt zitiert wird. Es klingt technisch aber der Prozess ist recht simple:
- Retrieval: Sub-Queries werden mit Suchindex abgeglichen. Ergebnisse werden als Liste zurückgegeben (Titel, URL, Snippet)
- Ranking: Suchergebnisse werden nach Relevanz, Autorität und Aktualität bewertet. Zu beachten: Modelle bewerten nicht Seiten als Ganzes, sondern einzelne Passagen, „Fraggles" (Fragments of Pages) bezeichnet. Ein selbstständig verständlicher Absatz von 50–150 Wörtern, der eine Sub-Query direkt beantwortet, wird von LLMs präferiert.
- Extraction: Das Modell ruft die vielversprechendsten URLs auf und liest den Seiteninhalt. Zu beachten: 63 % der ChatGPT-Agenten verlassen eine Seite sofort z.B. wegen HTTP-Fehlern, Redirects, langsamer Ladezeit, CAPTCHAs oder Bot-Blocking) Für Developer gilt außerdem zu beachten, dass ChatGPTs Crawler kein JavaScript rendert. Es wird das HTML extrahiert.
- Attribution: Aus den extrahierten Passagen wird die Antwort generiert. Nicht alle abgerufenen Quellen werden zitiert. Nur die, die einen spezifischen Claim in der Antwort stützen. Verschiedene Datenquellen zeigen, dass zwischen 70% und 85 % der abgerufenen Seiten nie zitiert werden. Hier weicht AEO von SEO ab. Seiten müssen teils umstrukturiert werden, um nicht nur gefunden, sondern auch zitiert zu werden.
Welche Content-Typen zitiert werden
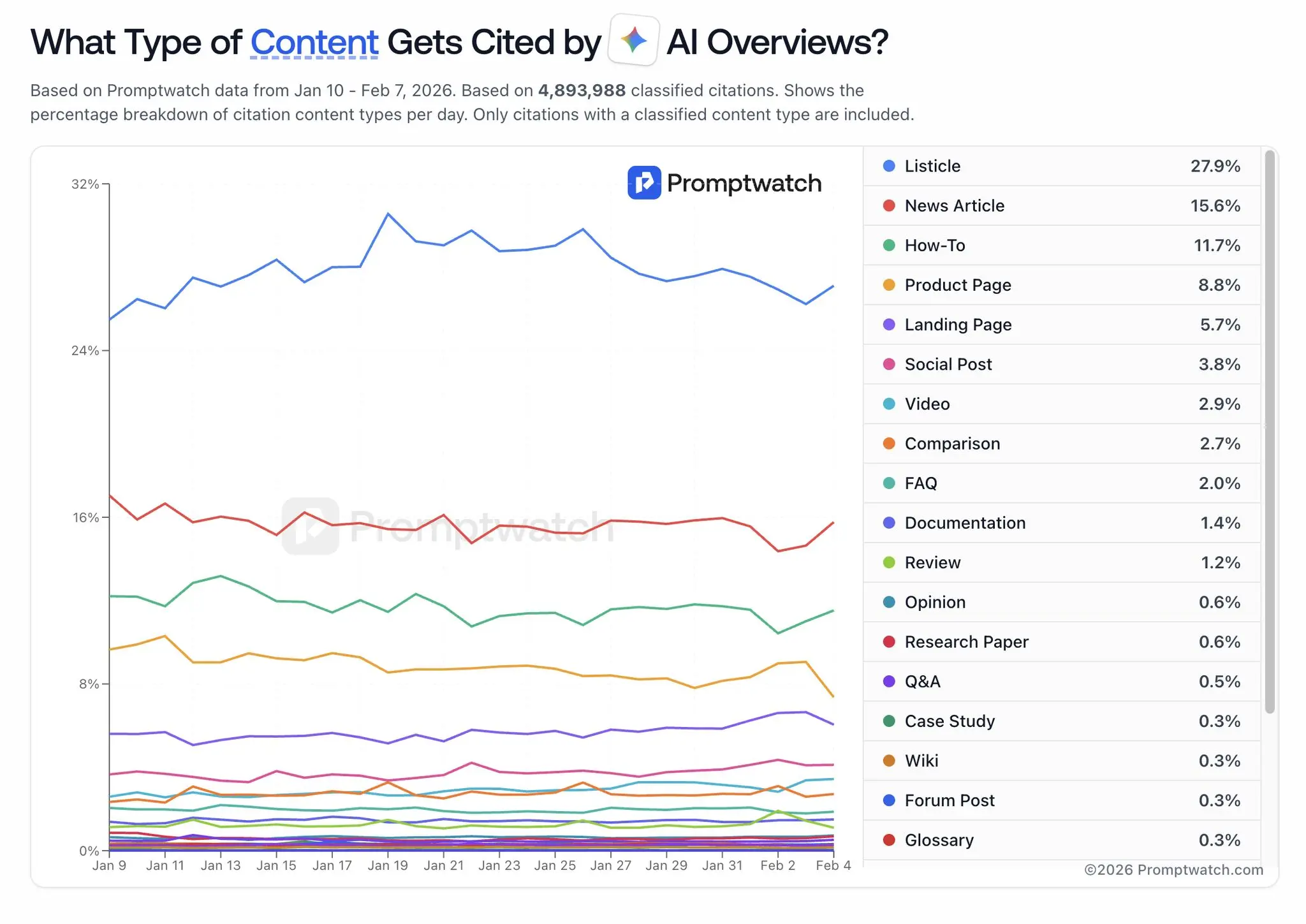
Promptwatch hat 4,9 Millionen klassifizierte Zitationen ausgewertet (Januar–Februar 2026):
Listicles dominieren mit 27,9 %. News-Artikel folgen mit 15,6 %, How-To-Inhalte mit 11,7 %. Product Pages erreichen 8,8 %, Landing Pages 5,7 %, Documentation 1,4 %.
Für B2B-Unternehmen mit erklärungsbedürftigen Produkten ergibt sich eine klare Hierarchie: Produktseiten allein erzeugen keine KI-Sichtbarkeit. Erklärende, vergleichende und anwendungsbezogene Inhalte - technische Guides, Vergleichsartikel, Anwendungsdokumentation - sind die Content-Typen, die Modelle zitieren. Die Expertise, die in Vertriebsgesprächen und technischen Dokumentationen existiert, muss als indexierbarer, strukturierter Web-Content publiziert werden.
Was wir bisher sehen
Wir arbeiten mit B2B-Unternehmen an ihrer KI-Sichtbarkeit. Das Tracking ist jung, die Datenlage entwickelt sich. Aber folgende Muster sind stabil:
SEO ist der wichtigste Faktor. Wer in den SERPs nicht auftaucht, existiert für LLMs nicht. Was wir daher machen: Jede relevante Buyer-Frage braucht eine eigenständige, indexierte Seite. FAQ-Sektionen werden zu einzelnen Seiten ausgebaut. PDFs werden als vollständige Artikel republiziert. Technische Datenblätter werden in die Content-Architektur integriert. Das ist keine Content-Farm, sondern maximiert die Queries, bei denen man Sichtbar ist. Je mehr relevante Seiten im Index, desto mehr Sub-Queries werden abgedeckt.
Titel und Meta-Description (noch) werden wichtiger. Das Modell sieht Titel und Snippet, bevor es entscheidet, ob eine Seite gelesen wird. Generische Titel („Unsere Lösungen", „Produkte") liefern kein Signal und werden oft nicht geklickt. Das ist gleichzeitig auch eine Oppurtunity für Seiten, die schlecht ranken. Laut Surfer SEO (173.902 URLs, Dezember 2025) stehen 68 % der von KI-Overviews zitierten Seiten nicht in den Top 10 der organischen Suchergebnisse.
Informationsdichte am Seitenanfang. Das „Lost in the Middle"-Phänomen (Liu et al., Stanford/Meta, TACL 2024) zeigt: LLMs gewichten Informationen am Anfang und Ende eines Inputs signifikant stärker als in der Mitte. Für Content heißt das: Der zentrale Claim jedes Abschnitts gehört in die ersten zwei Sätze. Idealerweise sollte jeder H2-Block als eigenständiges Fragment funktionieren. Dazu kommt der Aktualitätsfaktor: 76 % der am häufigsten von ChatGPT zitierten Seiten wurden in den letzten 30 Tagen aktualisiert.
Wichtig & Underrated für DACH
Bing. Die meisten deutschen B2B-Unternehmen haben Bing nie als Kanal betrachtet. Mit ChatGPTs Marktdominanz ist das ein strukturelles Versäumnis. Wie Ihre Seiten in Bing indexiert sind, lässt sich gut über die Bing Webmaster Tools prüfen.
Dual-Language Fan-Out. KI-Modelle generieren Sub-Queries in mehreren Sprachen. Ein deutscher Prompt erzeugt häufig auch englische Sub-Queries. Ein Hersteller mit ausschließlich deutschsprachigem Content verliert systematisch Fan-Out-Abdeckung auf englischsprachige Sub-Queries.
JavaScript-Rendering. Wie gesagt: ChatGPTs Crawler rendert kein JavaScript. Viele DACH-B2B-Websites setzen auf JS-Frameworks ohne Server-Side Rendering. Für den Crawler zeigen diese Seiten leeren Code. Google rendert JavaScript - ChatGPT nicht. Dieselbe Seite, zwei völlig unterschiedliche Sichtbarkeiten.
Fazit
Um in LLMs zitiert zu werden, benötigt man die drei Bausteine von SEO:
- Content
- Autorität
- Saubere technische Infrastruktur
Die Landschaft ändert sich und diktiert, welcher Content veröffentlicht werden sollte und wie dieser aufbereitet werden muss. Wir bieten eine kostenlose Bestandsanalyse an (Audit + 30 min Google Meet).
